

A complete RAG system contains several flexible modules, such as document collections (corpora), retrieval algorithms(retrievers), and backbone LLMs, but the best practices for tuning these components are still unclear, hindering their optimal adoption in medicine. Following are some research and implementation related:
Clinical RAG Paper Reading
Almanac: Retrieval-Augmented Language Models for Clinical Medicine
Language models as clinical knowledge-bases with the ability to use external tools such as search engines, medical databases and calculators to answer queries related to clinical concepts and latest treatment recommendations.
The research result suggests that retrieval systems can effectively facilitate information retrieval.
The complete retrieval system starts with a query, Almanac follows the below steps:
Uses external tools to retrieve relevant information like Tavily search, etc
Synthesizing a response with citations referencing source material
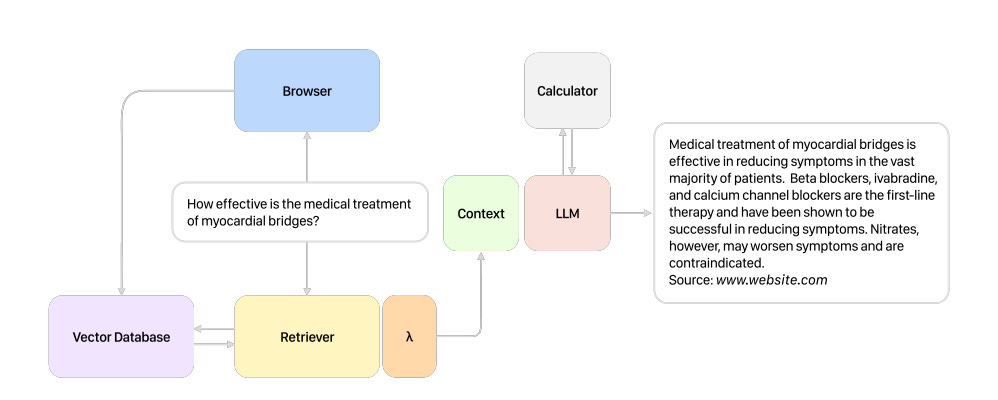
Spotlight of Almanac:
Dynamic Retrieval:
Local Documents
MedRAG: Benchmarking RAG for Medicine
RAG is for solving hallucinations and outdated knowledge. MEDRAG’s experiment result show that the combination of various medical corpora and retrievers achieves the best performance. Also, a log-linear scaling property and the “lost-in-the-middle" effects in medical RAG.
The performance of one RAG system is strongly related to the corpus it selects.
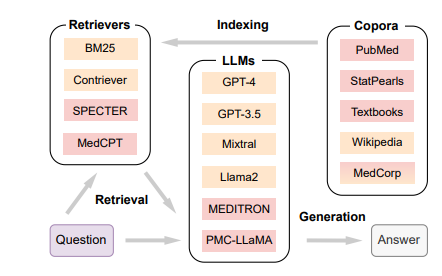
Retrievers:
Lexical Retriever: BM25
Semantic Retriever: Contriever, SPECTER, MedCPT
LLM
with CoT
with MedRAG + CoT
Copora: General & Specific info source
Wikipedia
PubMed, StatPeals, Textbooks, MedCorp
STORM
Clinical Multimodal Paper
PanDerm: A General-Purpose Multimodal Foundation Model for Dermatology
PanDerm is a multimodal dermatology foundation model pretrained on over 2M images. In pretraining stage, PanDerm employs a novel combination of masked latent modeling and CLIP feature alignment for self-supervised learning, also surpassed vision-language models such as CLIP 37, MONET 41 and BiomedCLIP 42 in benchmark evaluations. Common tasks include:
Total body skin examination
Risk assessment at both patient and lesion levels
Differentiation of neoplastic from inflammatory diseases
Multimodal image analysis
Pathology Interpretation
Monitoring lesion changes
Predicting outcomes
Modalities include: total body photography (TBP), dermatopathology, clinical, dermascopic images.
Core concepts:
Ablation study: a method commonly used in ML/DL to assess the importance of different component or features of a model. The main idea is to understand which parts of a model contribute most to its overall performance.
CLIP-based Teacher Model: Contrastive Language-Image Pretraining has two encoders, contrastive training, and zero-shot learning.
CLIP-Large:
ViT-large 38 encoder: A vision transformer model to process images, ViT-large 38 would refer to a model with 38 transformer layers and likely more hidden units per layer than smaller models.
A regressor:
BiomedGPT: A Generalist Vision-Language Foundation Model for Diverse Biomedical Tasks
BiomedGPT is the first open-source and lightweight vision-language foundation model, designed as a generalist capable of performing various biomedical tasks. A large-scale pre-training corpus comprising 592,567 images, approximately 183 million text sentences, 46,408 object-label pairs and 271,804 image-text pairs.
Key Concepts:
Masked Modeling
Reference
Postgres pgvector Extension - Vector Database with PostgreSQL / Langchain Integration
OpenAI Embeddings and Vector Databases Crash Course
Mixpeek & FLUX for Multimodal RAG